
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 딥러닝
- 데이터사이언스
- 개념정리
- github
- sql
- 변수
- 1주차
- python
- data
- 프로젝트
- 파이썬문법
- 데이터사이언티스트
- 2주차
- ML
- 빅쿼리
- AI
- 부트캠프
- Jupyter Notebook
- 깃허브
- 머신러닝
- 모두의연구소
- 주피터노트북
- 딕셔너리
- 데이터
- error
- bigquery
- 회고록
- 회고
- 파이썬
- 함수
[AIFFELTHON] 기업 프로젝트 (누설 자속 탐상기 검사 데이터 기반 예지보전 시스템 구축) 본문
아이펠톤[기업 프로젝트] 회고 (2025.07.22~09.18)
아이펠톤은 약 두 달간 특정 도메인 기업의 현직자와 함께 실제 과업을 해결하는 팀 프로젝트다.
그동안 부트캠프 과정에서 배운 다양한 이론과 기술을 직접 적용해 볼 수 있으며, 현직자 멘토링을 통해 특정 도메인을 이해하고 실무 기술을 배울 수 있다.
이 글은 그 과정에서 무엇을 고민했고, 어떻게 풀어나갔는지, 그리고 느낀 점들을 되돌아보기 위한 회고이다.
# 긴 글 주의
1. 프로젝트 소개
누설자속탐상기의 장비 교정 시기 탐지 - 예지보전 ( Predictive Maintenance, PdM)
생산설비의 고장은 제조라인 전체를 정지시키는 요소다.
이로 인한 생산 손실, 납기 지연, 품질 불량은 제조 기업의 신뢰도와 수익성을 크게 훼손할 수 있다.
이를 해결하기 위한 최신 접근 방식이 바로 예지보전이다.
'예지보전'이란?
설비의 데이터를 분석하여 이상 징후를 사전에 파악하고 조치하는 유지보수 방법이다.
장비 고장을 사전에 예측하고 예방 조치를 실행하는 전략으로, 단순한 유지보수를 넘어 데이터 기반의 지능형 설비 운영을 가능하게 한다.
| 예지보전 이점 | 설명 |
| 비용 절감 | 예기지 못한 고장으로 인한 생산 중단 시간과 수리 비용을 줄일 수 있다. |
| 생산성 향상 | 설비 가동률을 높이고, 예측 가능한 방식으로 유지보수를 수행하여 생산 계획의 변동성을 줄인다. |
| 설비 수명 연장 | 부품의 수명을 최적화하고, 꼭 필요한 부분만 보수하여 설비의 전반적인 수명을 연장할 수 있다. |
1-1) 프로젝트 개요 및 배경
문제 정의
실제 검사 현장에서는 정합성을 유지하기 위해 주기적인 교정이 필수적이다.
그러나 생산 스케줄로 인해 이상적인 주기로 교정을 수행하기 어려워 이미 이상 징후가 발생한 후에 교정이 이루어진다.
이로 인해 품질 저하와 생산성 손실 문제로 이어지며, 제조 기업의 신뢰도에도 영향을 미친다.
핵심 목표
"신호의 패턴을 분석하여 교정 시점 정의 & 예지보전을 위한 시스템 구축"
구체적으로는:
- 강종별 base noise 기준선 설정
- 과거 데이터 분석을 통해 장비 교정 시점 정의
- ML/DL모델을 활용한 base noise 예측으로 새로운 검사 실행 시 장비 교정 시점 알림
분석 결과는 streamlit 기반 대시보드 프로토타입으로 구현하여 현장 모니터링 가능하게 한다.
1-2) 프로젝트 일정 및 팀 구성
일정: 2025.07.22~09.18 (약 2달간 진행)
팀 구성: 5명(팀장 1명, 팀원 4명(✓))
역할: 데이터 분석 및 시각화(✓), 예측 모델링(✓), streamlit 화면 구현
2. 데이터 및 기술 스택
2-1) 어떤 데이터를 사용했는가?
- 결측치, 0값 오류 등 전처리 진행한 데이터로 활용( # 개인_기여_모먼트⭐⭐)
- 공정에서 봉강 결함을 검사하며 출력되는 10개의 센서 값(원시 데이터)
- LOT 메타 데이터
- MCAL 데이터

2-2) 어떤 기술이 들어갔는가?
Python (pandas, numpy, scikit-learn, lightgbm, catboost, tensorflow/pytorch)
Visualization : matplotlib, seaborn, plotly
Dashboard : Streamlit
LLM Integration : Gemma3 4B (llama.cpp 기반)
Collaboration : GitHub, Google Drive, Notion
3. 아키텍처 / 파이프라인
4. 기능 설명
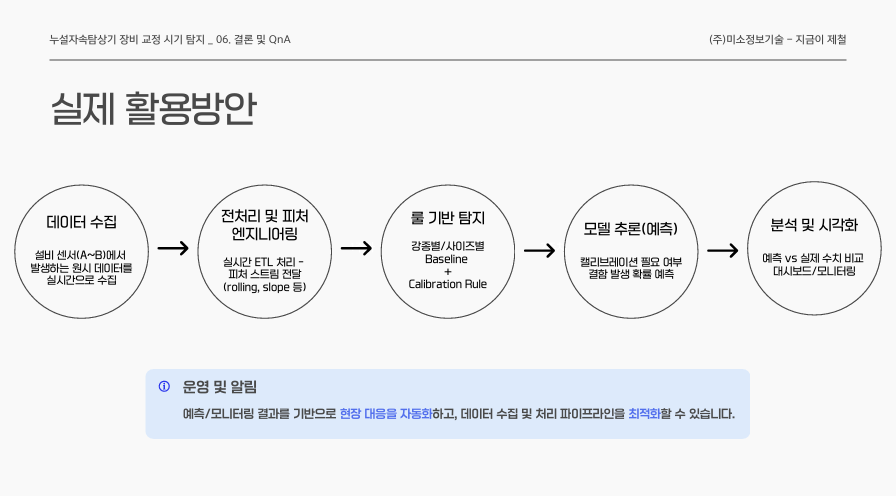
본 프로젝트는 분석 결과를 'Streamlit 기반 대시보드'로 구현하여 현장에서 모니터링이 가능하도록 하였다.
- LOT 단위 조회
- 연속 공정 보기 (전체 흐름 시각화)
- 특정 LOT 검색 및 채널별 신호 확인
- Rule 기반 필터링
- 교정 필요 LOT 탐지 (Rule 1~5 적용 여부 선택)
- 직전/후 MCAL 센서의 dB와 검사 결과 표시
- Weak(1개 조건 충족) / Strong(2개 이상 충족) 모드 지원
- 이벤트 표시
- LOT 변경, 강종 변경, CAL(교정 시점) 마커 표시
[참고 이미지 1]

[참고 이미지 2]

[참고 이미지 3]

4. Gemma 모델 통합
- LOT별 교정 필요 사유 직관적 설명 기능 제공
[참고 이미지]

5. 데이터 분석
기존 접근법 '단순 이상치'를 교정 필요 시점으로 오인
- 실제 교정 시점과의 괴리
- 튀는 구간으로 모든 교정 필요 시점을 정의하기에는 근거가 부족
⬇
분석 방향의 전환 일시적 튐이 아니라 흐름의 변화를 보자!
- 5가지 룰 베이스 탐지 설정
- 교정 시점에 영향을 미치는 요인 탐색
# 개선된 접근법
1. 다중 규칙 기반 탐지
- Rule 1: 시작–끝 Level Shift
- Rule 2: Baseline 대비 지속적 편차
- Rule 3: 추세 변화 / 크로스 채널 이탈
- Rule 4: 단일 채널 급락
- Rule 5: 전채널 우하향 패턴 제외
→ 최종적으로 162개 LOT (30.3%)가 교정 필요 후보로 탐지됨
# 개인_기여_모먼트⭐⭐
2. 센서 민감도(dB)와 교정 시점의 연관성
- 센서 민감도(dB)
- 시간 순서 고려(시계열 데이터 반영)
- 봉강 검사 결과의 No Good 개수/비율
→ 최종적으로 dB와 센서 출력값의 상관관계를 도출하여 교정 예측 시기 정의 및 근거 마련
6. 모델링
Task 1. 바로 다음 봉강(T+1) 예측
활용 모델: RandomForest, LSTM( # 개인_기여_모먼트⭐⭐)
한계점: 단기 예측에서는 자기상관성 과대평가 위험
# 개인_기여_모먼트⭐⭐
Task 2. LOT 메타데이터 기반 (T+10) 예측
활용 모델: CatBoost
한계점: 시계열 특성 반영 x, 피처 제한적
# 최종 선정 모델
Task 3. Past N → Future 10 (T+10) 다변량 예측
활용 모델: LightGBM 모델 + 600개 피처, LSTM 모델( # 개인_기여_모먼트⭐⭐)
성능: R² 0.73 MAE 0.0065 (LightGBM), R² 0.2 MAE 0.014 (LSTM)
한계점: 특정 강종을 위해서는 별도의 Rule 보강이나 LOT 병합 방안이 필요
피드백:
- 절대치 예측은 현장에서 발생하는 100가지 이상의 요인들에 영향을 받음 → 실질적으로 예측은 거의 불가
- 추세 기반 확률 예측 이 더 유용하다는 피드백
7. 문제 해결
# 개인_기여_모먼트⭐⭐
# 시간 순서로 작성
고민 1 - 데이터 정합성 및 품질 확인
팀원들과 데이터를 분석하기 전에, 일부 파일에서 결측치나 0 값 오류 등 전처리가 필요함을 발견했다.
각 파일의 문제점을 노션에 정리하여 팀원들과 공유하고, 전처리를 수행함으로써 데이터 품질을 높이고 팀원 간 통일된 데이터를 기반으로 분석할 수 있도록 했다.

고민 2 - 데이터 분석 접근법
1차 접근법 'Base Noise' 0-0.3V 구간 집중 분석
센서 데이터 중 안정적인 수치라고 불리는 base noise 기준 0-0.3v 구간 내의 데이터에 집중했다.
이 구간은 안정적이어야 하므로 발생하는 미세한 변화가 장비 교정 시점과 관련 있을 거라고 생각했다.
"이상치 발생 시점이 교정 시점과 일치할 것이다"
- 강종별 사이즈별 base noise 기준치를 잡아 이상치를 설정
- 이상치 발생 원인 분석 및 정의(Fault Diagnostics)
- 정의를 바탕으로 교정 시점 예측 시도
- 실제 교정 시점과 예측 시점의 차이로 정확도 검증(Prognostics Distance, Prognostics System Accuracy)
한계점 : 0-0.3v 안정 구간에만 집중했던 방식으로는 결함으로 인한 자연스러운 Peak를 포착하기 어려움
방향성 제시 : 이에 결함으로 인한 Peak점 데이터를 제거하고, 더 넓은 데이터 범위를 활용하여 전체적인 변화와 맥락을 분석
2차 접근법: 결함 Peak 제거 후 전체 데이터로 집중 분석
정제된 전체 데이터를 대상으로 정상적인 Peak 데이터는 모두 제거하였으므로, 여전히 이상치가 보인다면 교정 시점과 관련이 있을 거라고 생각하였다.
"결함으로 인한 정상적인 이상치 제거 후에도 보이는 이상치 시점은 교정 시점과 일치할 것이다"
- 강종별 사이즈별 base noise 기준치를 다시 잡아 이상치를 설정
- 이상치 전후 시점 분석(변동계수, 센서별 상관관계 등)
- 위와 같은 방식으로 진행
한계점: 센서의 특정 이상치는 정상적인 현상일 수도 있겠다는 결론 도출.(단순 이상치 ≠ 교정 시점)
방향성 제시: 정상일 수도, 비정상일 수도 있는 이상치에 대해 이 두 가지 경우를 명확히 구분할 수 있는 요인을 데이터 안에서 찾아내는 것이 다음 분석의 핵심
3차 접근법: 센서 민감도와 교정 시점 상관관계 결론 도출
복잡하고 패턴 없는 데이터에서 교정 시점에 영향을 주는 요인이 어떤 건지 찾는 것은 쉬운 일이 아니었다.
(안 본 게 없고, 안 해 본 게 없는 것 같은데)
이전 분석에서는 간과했던 새로운 관점들을 가설로 세우며 깊이 탐색하였고, 수많은 시행착오 끝에!! 비로소 문제 해결의 핵심 열쇠를 찾아냈다.
"base noise가 우상향 패턴 -> 높은 확률로 센서 고장"
- 센서 민감도(dB): 센서 민감도 변화 바탕으로 센서 고장 여부 파악 가능
- 봉강 검사 결과에서 No Good(=결함) 비율/개수: dB와 흐름 변화를 통해 비정상적인 특이점이 발생 시 교정 시점 가능성
- 시간 순서(시계열 데이터 특성 반영)
팀원들이 통계치 기반으로 우상향 기준을 설정해 주었고, 내가 분석한 센서 민감도와의 연관성을 정의하여 기업에서 원하는 진정한 인사이트를 제시할 수 있었다.
해당 가설의 검증까지 확인하였고, 문서화하여 현직자분께 보내드렸다.
최종 인사이트 제시 및 실질적인 활용 방안
우상향 패턴은 세라믹슈 마모의 전조 신호로 활용하여, 현장에서는 streamlit을 통해 센서 출력값을 모니터링하며 우상향 패턴이 보인다면 사전에 조기 점검으로 저품질 생산을 막을 수 있다는 비즈니스적 가치를 제안하였다.

고민 3 - 모델링 접근법
t+1 시점의 대푯값 예측, t+10 시점의 다변량 예측을 ML/DL로 다양하게 시도해 보았다.
1차 접근법: 바로 다음 t+1 시점의 봉강 대푯값 예측
# LSTM Model
# 장기 의존성 학습, 복잡한 비선형 패턴 학습 용이하여 선택
===== Evaluation Metrics =====
MSE : 0.000149
RMSE : 0.012190
MAE : 0.008569
R2 : 0.5552
한계점
- 자기 상관성으로 점수가 부풀려 나옴
- 실제 현장에서는 약 5초 내에 다음 봉강의 검사값이 바로 산출되므로 t+1 예측 자체의 실용성 제한
개선 사항
- t+1 예측 → t+10 센서값 예측으로 문제 정의 변경
- mlft 검사 시작 전/후 성능 비교
깨달은 점
- 성능 지표뿐 아니라 자기 상관성 같은 본질적 문제와 실질적 비즈니스 가치를 함께 고려해야 함
2차 접근법: 검사 시작 전, LOT 메타데이터를 활용한 t+10 시점의 센서 10개 값 예측(다변량 예측 모델링)
# Catboost Model
#다중출력, 범주형 처리 강점으로 선택
===== Evaluation Metrics =====
# 각 채널별 편차 존재
RMSE : 약 0.01
MAE : 약 0.01
R2 : 약 0.02
한계점
- 입력 변수(X)가 단순 메타데이터에 한정 → 세밀한 변동 반영 불가, 시계열 특성 적용 x
개선 사항
- 실시간 공정 적용(mlft 검사 시작 후)을 고려하여 t+10 시점의 10개 센서값 예측으로 문제 정의 변경
깨달은 점
- 예측값이 동일하게 나오는 문제는 시간 순서를 고려했을 때, 입력 피처가 제한적이어서 특정 시점에 같은 입력 변수값이 들어가기 때문이었다. 따라서 시계열 피처를 생성하여 이를 반영한 변수를 사용해야 함을 알게 되었다.
3차 접근법: 검사 시작 후, 과거 50개로 미래 t+10 시점의 센서 10개 값 예측(다변량 예측 모델링)
# LSTM Model
# 다변량 예측 모델로 선택
===== Evaluation Metrics =====
MSE : 0.0004
RMSE : 0.020
MAE : 0.014 ~ 0.015
R2 : 약 0.10 ~ 0.20 (채널별 편차 존재)
초기에는 자기 상관 모델을 구현하였으나, 오차 누적 이슈와 't+10 시점' 센서 10개 값 예측이라는 목표에 더 적합한 Direct LSTM Model을 개발하였다.
특히 데이터 누수 방지를 위해 전처리와 정규화 과정에서 shift 적용과 훈련/테스트 셋 분리에 세심한 주의를 기울였다.
또한, 시계열 데이터 특성을 고려해 TimeSeriesSplit 검증 방식으로 모델의 신뢰도를 확보하였다.
한계점
- 현직자 분께서 미래 시점의 base noise 예측은 100가지 이상의 현장 요인이 영향을 주기에 사실상 불가능하다는 피드백
- base noise 절대치 예측보다는 교정 필요 확률 예측이 더 실용적일 것이라는 피드백
7. 성과
7-1) 비즈니스 효과
- 데이터 기반 의사결정: 기존 작업자 경험 의존 → 데이터 기반 교정 판단 전환
- 생산성 향상: 적시 교정으로 불필요한 다운타임 감소
- 품질 안정화: 교정 지연으로 인한 불량률 감소
7-2) 기능적/기술적 성과
- Rule 기반 탐지: LOT의 30.3%를 교정 필요 후보로 검출
- dB와 교정 시점 상관관계 도출: dB값 변화 / 교정 시점 / base noise 상승과 연관성 정의, 근거 마련
- ML/DL 모델링: 최고 모델 성능 R² 0.73, MAE 0.0065 달성
- Streamlit 대시보드: Rule 탐지 + LOT 이벤트 마커 시각화 및 LLM 설명 기능 통합
8. 아쉬운 점 / 느낀 점
8-1) 아쉬운 점
데이터 분석
프로젝트 초반에 base noise를 강종/사이즈별로 예측하여 사전 '이상 탐지'하는 것에 초점을 맞췄지만, 실제로 모델링은 사실상 불가하단 피드백과 '예지보전' 시스템 구축을 위한 '데이터 분석'이 가장 중요하다는 것을 뒤늦게 깨달았다.
발표 후 그루 분을 통해 예지보전(PdM, PHM)이라는 이론적 개념과 PHM 시스템 개발 프로세스(Sensing, Feature Extraction, Diagnosis, Prognosis)의 존재를 알게 되었다.
만약 프로젝트 초기부터 이러한 지식을 알았다면 문제 정의에 훨씬 수월했을 것이라는 아쉬움이 크다.
그래도 여러 시행착오를 겪으며 더 깊이 있는 분석을 시도해 보았기에 제조업 도메인과 해당 데이터의 의미와 특성을 잘 파악할 수 있었다고 생각한다.
모델링
모델 구조, 자기 상관, direct 방식 등 부족했던 이해를 보완하는 과정에서 시간이 오래 걸리기도 했지만, 데이터 전처리·피처 엔지니어링·데이터 누수 방지 코드 구현 등을 통해 모델을 보다 깊이 이해할 수 있었다.
8-2) 느낀 점
무엇보다 개별 데이터를 분석해 실질적인 비즈니스 가치로 연결하는 과정이 생각보다 훨씬 어렵다는 것을 몸소 깨달았다. 이를 위해서는 해당 도메인에 대한 깊이 있는 이해와 각 데이터가 가진 의미를 정확히 파악하는 능력이 필수적임을 절감했다. 또한 이러한 과정을 팀원들과 끊임없이 소통하고 공유하는 것이 문제 해결뿐만 아니라 나의 이해도를 높이는 데에도 결정적인 도움이 되었다.
사실 프로젝트 중반까지도 원하는 결과를 도출하지 못했지만, 끝까지 포기하지 않는 팀원들의 집념 덕분에 최종적으로 문제를 해결할 수 있었다. 그 결과 초기 기획보다 훨씬 완성도 높은 산출물을 만들어낼 수 있었다.
복잡하고 어려운 데이터일수록 실제 현업에서 접하게 될 실무 데이터와 가깝다고 생각한다. 이번 경험을 통해 어떤 난해한 데이터 문제도 능동적으로 해결해 나갈 수 있다는 자신감도 얻게 되었다.
마지막으로 도움을 주신 현직자분들, 끝까지 최선을 다해준 팀원들, 그리고 팀을 든든하게 이끌어준 팀장 모두에게 감사드리며, 이번 프로젝트는 값진 경험으로 오래 기억될 것 같다.
9. 참고 자료
동영상 첨부
발표 자료 첨부
'Project' 카테고리의 다른 글
| [LangchainThon] 랭체인톤 (Reddit 커뮤니티의 TIFU 데이터를 활용한 AI 상담사 챗봇) (1) | 2025.07.06 |
|---|---|
| [DATATHON] 데이터톤 2015년 11월 매출을 예측(실적 관리, 상품 개발, 매장 운영 개선 지원) (3) | 2025.06.08 |

