
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 개념정리
- 파이썬
- 프로젝트
- 파이썬문법
- 주피터노트북
- 함수
- 깃허브
- 1주차
- 빅쿼리
- error
- 딥러닝
- 회고록
- 데이터사이언스
- Jupyter Notebook
- AI
- data
- 데이터
- github
- bigquery
- 모두의연구소
- 딕셔너리
- ML
- python
- 2주차
- 머신러닝
- 데이터사이언티스트
- 부트캠프
- sql
- 회고
- 변수
[MLOps] (2) Google Cloud Platform(GCP)란? Data Warehouse, Big Query, Vertex AI에 대한 이야기 본문
[MLOps] (2) Google Cloud Platform(GCP)란? Data Warehouse, Big Query, Vertex AI에 대한 이야기
jpocket 2025. 10. 15. 17:30클라우딩 컴퓨팅 환경은 현대 IT 산업에서 필수적인 요소다.
특히 한국에서는 AWS, GCP, Microsoft Azure 이 세 가지 주요 클라우드 플랫폼이 많이 사용된다.
강사님께서는 여러 클라우드 플랫폼 중에서도 GCP를 다루었다.
그 이유는, GCP가 머신러닝에 특화된 강력한 기능을 자체적으로 다수 보유하고 있어 MLOps 학습에 가장 적합하다고 하신다.
GCP의 BigQuery나 Vertex AI 같은 도구들은 머신러닝 모델을 개발하고 운영하는 전 과정에서 큰 도움을 주어, 많은 AI 엔지니어들이 선호하는 플랫폼이 되고 있다. 이번 글에서는 다음과 같은 내용을 다루어보았다.
학습 목표
- Google Cloud Platform(GCP) 이해
- 데이터 웨어하우스(DW)와 OLAP 이해
- BigQuery 이해 및 활용
- Data Warehouse vs. Data Lake vs. Lakehouse
- ETL vs. ELT
- BigQuery 아키텍처와 분산 시스템, 스트림 데이터 처리 이해
1. Google Cloud Platform (GCP) 소개
GCP는 특히 머신러닝(Machine Learning)과 빅데이터(Big Data) 분야에서 풍부한 서비스를 제공한다.
AI/ML과 데이터 분석에 필요한 다양한 도구를 한곳에 모아, 개발자가 복잡한 인프라 없이 핵심 로직에 집중할 수 있도록 돕는다.
강의에서는 AWS와 GCP를 비교하며 GCP의 이점을 설명한다.
AWS가 계정 기반으로 모든 컴포넌트를 통합 관리하는 반면, GCP는 프로젝트 단위로 서비스가 묶여 관리되는 것이 특징이다.
이러한 구조 덕분에 자원 할당과 권한 관리가 훨씬 유연해진다.
2. 데이터 웨어하우스(Data Warehouse, DW)와 OLAP
데이터 웨어하우스(DW)는 CSV 파일, 서비스 DB 등 다양한 소스의 데이터를 한곳에 모아 데이터를 분석하고 인사이트를 도출하기 위해 사용된다. OLAP 기반 DW의 특징은 개별 트랜잭션의 무결성이나 신뢰성은 보장보다는, 방대한 데이터를 빠르고 효율적으로 분석하는 데 강점이 있다.
BigQuery와 같은 데이터 웨어하우스는 바로 이 OLAP 기반 분석 도구이다.
| 구분 | OLAP (Online Analytical Processing) | OLTP (Online Transaction Processing) |
| 목적 | 대규모 데이터 분석 및 인사이트 도출 | 개별 트랜잭션 처리, 데이터 무결성 보장 |
| 사용 데이터 | CSV, 서비스 DB 등 다양한 소스의 집계 데이터 | 관계형 DB에 저장된 실시간 트랜잭션 데이터 |
| 특징 | 방대한 데이터를 빠르고 효율적으로 분석, 제품/로그 데이터 분석 적합 | 데이터의 원자성, 일관성, 무결성, 영속성(ACID) 보장 |
| 장점 | 대규모 데이터 분석에 최적화, 패턴/추세 발견 용이 | 신뢰성 높음, 오류 제어 뛰어남 |
| 단점 | 트랜잭션 처리에는 비효율적 | 대규모 데이터 분석에는 비효율적 |
| 대표 도구 | BigQuery, 데이터 웨어하우스 | SQL, MariaDB 등 관계형 데이터베이스 |
BigQuery는 쿼리의 복잡성과 데이터 용량에 따라 필요한 처리 유닛을 가변적으로 할당한다.
즉, 같은 쿼리라도 처리하는 데이터 양에 따라 비용이 크게 달라질 수 있다.
따라서 효율적인 쿼리 전략과 쿼리 작성 능력이 갖춰져 있어야, BigQuery를 비용과 성능 측면에서 최적화하여 활용할 수 있다.
실제로 BigQuery를 사용하는 기업에서는 쿼리 활용 능력을 중요하게 평가하며, 이는 효율적인 데이터 분석과 비용 관리에 직결되기 때문이다.
OLAP 기반의 데이터 웨어하우스는 BigQuery 말고도 다양하게 존재한다.
- Databricks
- Snowflake
- Amazon Redshift
3. Google BigQuery — 대규모 데이터 처리의 최강자
- 완전 관리형(Fully-managed)
- 버전 관리, 보안, 백업 등 복잡한 인프라 관리를 Google이 직접 담당
- 사용자는 인프라 관리 대신 데이터 분석에 집중 가능
- 탄력적인 계산 유닛 활용(Elastic Compute)
- 쿼리 복잡성과 데이터 용량에 따라 처리 자원을 가변적으로 할당
- 예시: 1억 개 데이터 → 200 유닛, 1조 개 데이터 → 2만 유닛
- 공개 데이터셋(Public Dataset)
- gsod, github_nested, wikipedia 등 다양한 공개 데이터셋 제공
- Colab 환경에서 바로 조회 및 pandas DataFrame으로 가공 가능
- 복합 데이터 타입(Complex Data Type)
- ARRAY, RECORD 등 복잡한 구조의 데이터 타입 지원
- 여러 값을 그룹화하거나, 집계 결과를 복잡한 구조체로 저장 가능
3-1. Data Warehouse vs. Data Lake vs. Lakehouse
| 구분 | 데이터 웨어하우스 (Data Warehouse) | 데이터 레이크 (Data Lake) |
| 형태 | 타입이 정해져 있고 격자무늬처럼 체계화된 구조 | 구조가 정해져 있지 않고 자유로운 형태 (binary, 이미지 등) |
| 데이터 정리 | 사전에 정리정돈 필요, 스키마 기반 저장 | 제약 없음, 자유롭게 저장 가능 |
| 분석 처리 | SQL과 같은 표준 쿼리문 사용 가능, 바로 가공·처리 가능 | SQL 사용 불가, 가공 시 Python, Scala 등 필요 |
| 장점 | 데이터 분석 효율이 높고 즉시 처리 가능 | 다양한 형태의 데이터를 즉각적으로 저장 가능, 머신러닝 학습용 데이터에 적합 |
| 단점 | 초기 데이터 적재 시 수고로움 존재 | 데이터를 사용할 때 가공 비용 발생, 분석 효율 낮음 |
| 비유 | 격자무늬, 체계화된 저장 | 호수처럼 자유로운 저장, 폴더 구조와 유사 |
당연히 Data Warehouse처럼, 데이터가 체계적으로 정리된 형태로 쌓여야 효율적인 분석이 가능할거라 생각했다.
강의를 들어보니, 또 막상 그렇지만은 않았다. 이 이유를 이해하기 위해서는 ETL과 ELT 개념을 알아야 한다.
3-2. ETL vs. ELT
| 구분 | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) |
| 정의 | 데이터를 추출(Extract) 후 목적 시스템에 맞게 변환(Transform)하고 적재(Load) | 데이터를 추출(Extract) 후 일단 저장(Load)하고, 필요할 때 변환(Transform) |
| 처리 순서 | Extract → Transform → Load | Extract → Load → Transform |
| 적재 방식 | 변환 후 정제된 데이터를 적재 | 원본 데이터를 먼저 적재 |
| 장점 | 정제된 데이터만 저장하므로 분석 시 신뢰성이 높음 | 원본 데이터 보존으로 데이터 손실 위험 적음, 필요 시 언제든 변환 가능 |
| 단점 | 변환 과정에서 데이터 손실 가능, 스키마에 맞지 않는 데이터는 적재 어려움 | 변환이 필요할 때 추가 작업 필요, 분석 전 변환 과정 발생 |
| 데이터 저장 적합성 | 데이터 웨어하우스 (정형화된 스키마 필요) | 데이터 레이크 (비정형/반정형 데이터 적합) |
| 트렌드 | 과거 방식 | 현대적 방식, 레이크하우스(Lakehouse)로 융합 추세 |
| 예시 | 소수점 포함 데이터를 정수형으로 변환 후 적재 → 원본 손실 | 원본 데이터 그대로 적재 → 필요 시 변환 가능 |
| BigQuery 활용 | 기존 DW 기반 적재 | BigLake를 통해 데이터 레이크의 장점 일부 채택 가능 |
즉, 정리를 해보자면,
예전에는 데이터를 추출한 후 변환하고 적재하는 방식(ETL)을 사용했다.
이 과정에서 데이터 손실이 발생하면 복구가 어렵고, 다시 추출 -> 변환 -> 적재해야 하는 번거로움이 있다.
따라서 요즘은 데이터를 저장소에 적재하여 필요할 때 변환하는 방식(ELT)을 사용한다.
원본 데이터 손실을 방지할 수 있고, 자유롭게 데이터를 저장할 수 있는 Data Lake 형태가 중요해졌다.
최근에는 Data Warehouse, Data Lake로 분류해서 보지 않고, 두 가지 강점을 결합한 Lakehouse 형태로 활용하는 추세다.
3-3. BigQuery Architecture - 효율적인 분산 시스템
BigQuery는 효율적인 분산 시스템 구조를 갖추고 있어, 배치 처리뿐만 아니라 실시간 데이터 처리에도 적합하다.
이 때문에 로그나 이벤트 스트림과 같은 스트림 데이터를 BigQuery를 통해 분석하고 처리하는 사례가 많다.
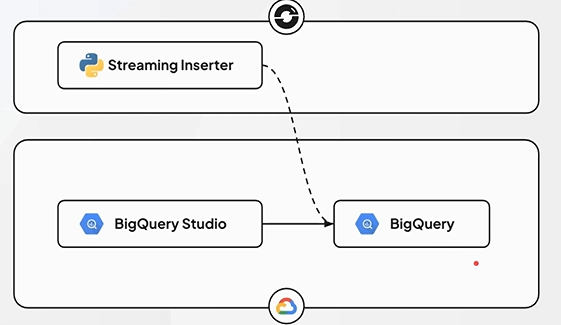
Streaming Inserter가 BigQuery에 데이터를 넣어주고 있는 형태다.
BigQuery Studio는 BigQuery 엔진에 저장되어 있는 데이터를 원할 때 직접 쿼리문을 작성해서 볼 수 있다.
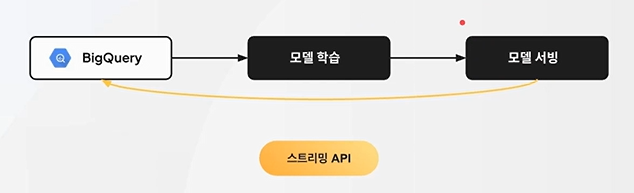
머신러닝 모델은 데이터를 기반으로 패턴을 학습하고, 이를 통해 실제 문제를 예측하고 해결한다.
하지만 초기 데이터가 부족하다면? 당연히 모델 학습이 어려워진다. 이를 "Cold Start"문제라고 한다.
해결 방법: Rule-based 시스템으로 초기 서비스를 운영하며 데이터를 수집 → BigQuery 스트리밍으로 빠르게 적재 → 모델 학습에 활용한다. 이러한 과정은 Flywheel 구조와 유사하다.
좋은 제품 → 많은 유저 → 많은 데이터 → 더 좋은 모델 → 더 좋은 제품 → 더 많은 유저 → ...
이처럼 선순환 구조를 통해 머신러닝 모델과 서비스가 자동으로 개선되도록 데이터 파이프라인과 개발 생애주기를 설계하는 것이 핵심이다. 이렇게 점진적으로 "Cold Start" 문제를 해결할 수 있다.
이후, 뉴스 카테고리 분류 모델 만드는 것을 주제로 실습을 진행하며 수동 관리의 문제점을 확인하였다.
(PyTorch + BertForSequenceClassification)
- 모델, 패키지, 버전 관리 어려움
- 로컬 서버 삭제 시 데이터 손실 위험
- GPU 환경 설정 포함되지 않음
- 배포 자동화가 불가
데이터 수집: Huggingface https://huggingface.co/datasets/wangrongsheng/ag_news
wangrongsheng/ag_news · Datasets at Hugging Face
State grant to aid Lynn; Bank gives Salem \$10k Central Square in Lynn should be looking a bit brighter. New sidewalks, curbs, fences, lights, landscaping, and road improvements are planned for the Gateway Artisan Block, a key area of the square, with \$83
huggingface.co
강의는 모델 학습 흐름을 분석하여 데이터 출처와 학습 활용 방식을 확인하고, 데이터 파이프라인을 통해 수동 관리의 문제점이 해결되는 방향으로 진행된다.
이를 통해 ML 학습, 서빙, 평가, 운영을 한 곳에서 관리할 수 있으며, 자동화된 파이프라인으로 모델 학습과 개선 과정을 간소화할 수 있다.
다음 게시글에서는 MLOps 파이프라인 구축 과정을 이어서 다룰 예정이다.
'MLOps' 카테고리의 다른 글
| [MLOps] (1) MLOps란? MLOps 배경, 소개, 전망에 대한 이야기 (0) | 2025.10.15 |
|---|