
Notice
Recent Posts
Recent Comments
Link
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- 개념정리
- data
- 회고록
- AI
- 데이터사이언스
- 데이터사이언티스트
- 변수
- bigquery
- 주피터노트북
- 파이썬
- Jupyter Notebook
- 딥러닝
- ML
- 머신러닝
- python
- 회고
- 깃허브
- error
- 부트캠프
- 파이썬문법
- 모두의연구소
- sql
- github
- 프로젝트
- 함수
- 딕셔너리
- 데이터
- 1주차
- 빅쿼리
- 2주차
Archives
[ML] 비지도학습 - 군집화(Clustering) 본문
반응형
파이썬 머신러닝 완벽 가이드 | 권철민 - 교보문고
파이썬 머신러닝 완벽 가이드 | 자세한 이론 설명과 파이썬 실습을 통해 머신러닝을 완벽하게 배울 수 있습니다!《파이썬 머신러닝 완벽 가이드》는 이론 위주의 머신러닝 책에서 탈피해, 다양
product.kyobobook.co.kr
1️⃣ p431-436 KMeans 알고리즘
- KMeans 객체 생성 → fit() 으로 학습 → labels_ 로 군집 결과 확인
- 시각화를 위해 PCA로 2차원 평면에 차원 축소 후 시각화
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3)
kmeans.fit(data)
labels = kmeans.labels_
# 한 줄로 정리
labels = kmeans.fit_predict(data)2️⃣ p437-441 군집화 테스트 데이터 생성
- make_blobs() 함수로 군집화 테스트용 샘플 데이터 생성
- fit_predict() 사용 시 학습 + 예측 결과 한번에
3️⃣ p441-445 군집 평가 - 실루엣 분석
- 실루엣 계수(Silhouette Score)

- 값 범위: -1 ~ 1
- 1에 가까울수록 잘 분리된 좋은 군집화
4️⃣ p445-449 실루엣 시각화 → 군집 수 최적화
- 군집 수에 따른 평균 실루엣 계수 시각화
- 단순히 실루엣 계수가 가장 높은 군집 수가 항상 최적은 아님

5️⃣ p449-455 평균 이동(Mean Shift)

- 커널 밀도 추정(KDE) 기반
- 모든 데이터에 커널 함수를 적용 → 확률 밀도 함수(PDF) 계산
- 가우시안 커널 사용
- 대역폭(h) 작으면: 과대적합, 군집 많아짐
- 대역폭(h) 크면: 과소적합, 군집 적어짐
6️⃣ p455-463 GMM (Gaussian Mixture Model)
- 여러 개의 정규분포 조합 → 확률 기반 군집화
- 각 군집을 타원형 분포로 모델링
- KMeans와 차이점
- KMeans: 단 하나의 군집에 소속
- GMM: 각 데이터가 여러 군집에 속할 확률 계산
- 타원형 군집에 더 잘 맞음
7️⃣ p463-473 DBSCAN (Density-Based Spatial Clustering)
- 밀도 기반 군집화 알고리즘
- 주요 하이퍼파라미터
- eps: 반경 (거리)
- min_samples: 이웃으로 간주하기 위한 최소 이웃 수
- 밀도가 높은 지역은 군집으로, 그렇지 않으면 노이즈로 간주
✅ 요약
| KMeans | 원형 중심, 빠름 | 간단하고 구 모양의 군집 |
| GMM | 타원형 분포, 확률 기반 | 군집 모양이 다양할 때 |
| MeanShift | 자동 군집 수 결정, KDE 기반 | 커널 대역폭 조정으로 유연하게 군집화 |
| DBSCAN | 밀도 기반, 노이즈 감지 | 밀도 차이가 있는 데이터, 도넛 모양 |
전체적인 머신러닝 과정에 대해 배웠던 내용을 도식화하여 나타내보았다.
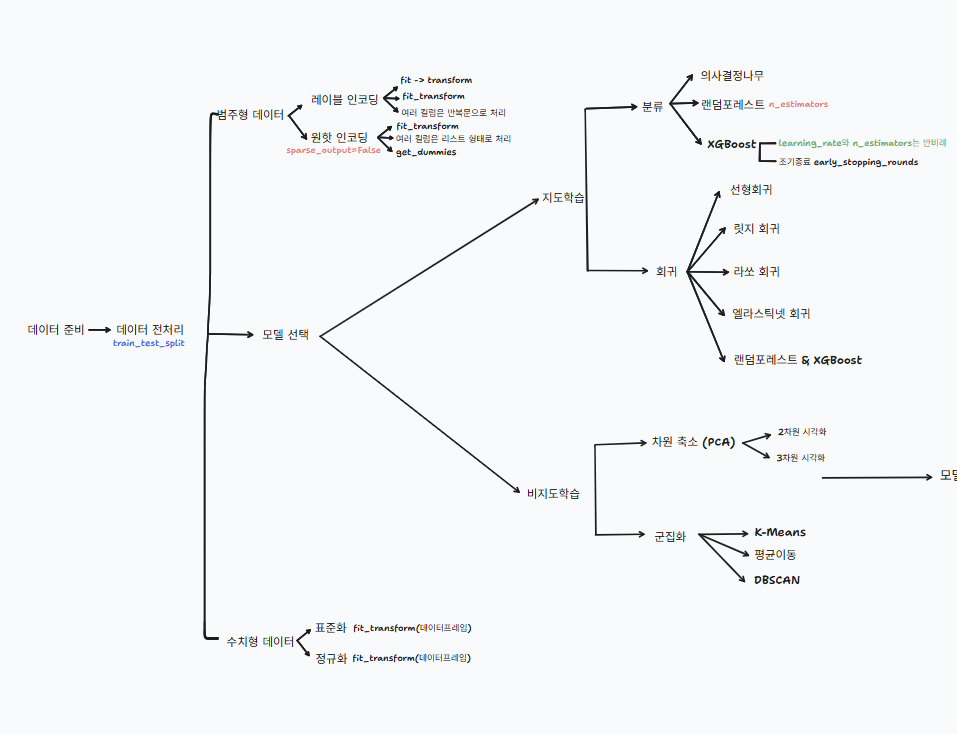
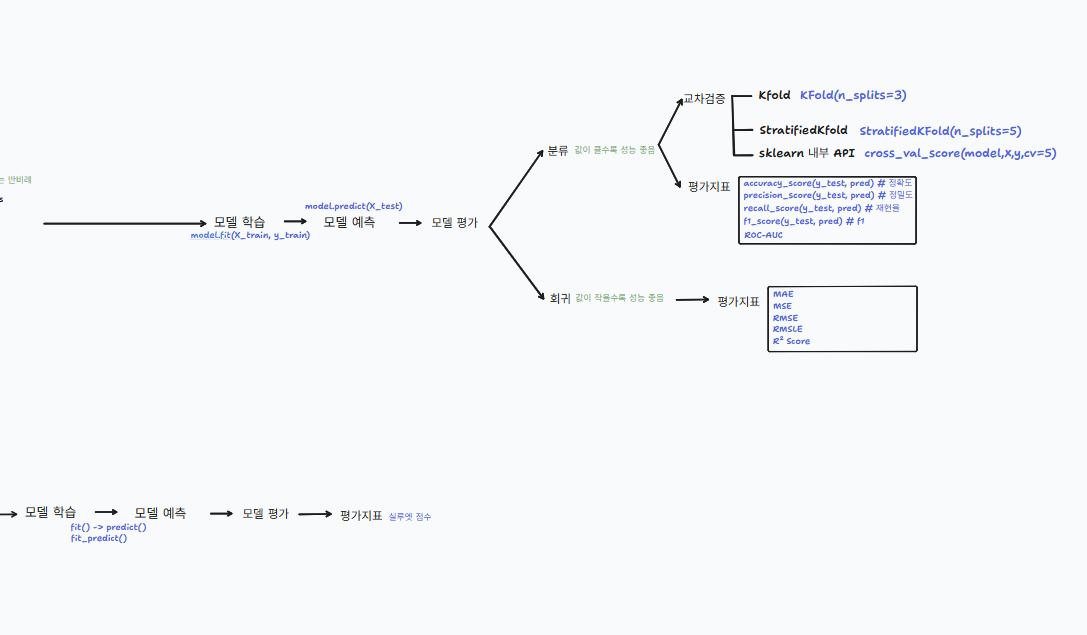

'Machine Learning' 카테고리의 다른 글
| [시계열] 시계열 데이터, 시계열 데이터 성질, 시계열 데이터의 EDA (5) | 2025.05.22 |
|---|---|
| [ML] 지도학습(회귀) 모델, 하이퍼파라미터 튜닝, 모델 평가 (1) | 2025.05.14 |
| [ML] 지도학습(분류) 모델, 하이퍼파라미터 튜닝, 모델 평가 (0) | 2025.05.12 |
| [ML] Machine Learning 머신러닝 과정 정리 (코드로 이해하기) (1) | 2025.05.08 |
'Machine Learning' Related Articles
more



