
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 데이터
- 프로젝트
- 데이터사이언스
- bigquery
- sql
- 데이터사이언티스트
- 주피터노트북
- 깃허브
- 회고
- 변수
- 딕셔너리
- github
- 함수
- 파이썬문법
- 부트캠프
- 머신러닝
- 2주차
- 개념정리
- 1주차
- AI
- Jupyter Notebook
- 파이썬
- 딥러닝
- 회고록
- python
- data
- 모두의연구소
- ML
- 빅쿼리
- error
[딥러닝] 텍스트 데이터를 문자열로 저장하기, 파일과 디렉터리 본문
1. 텍스트 데이터를 문자열로 저장하기
1) 인코딩과 디코딩
2) 문자열 다루기
3) 정규 표현식
2. 파일과 디렉터리 다루기
1) 파일 다루기
2) 디렉터리 다루기
3) 모듈과 패키지
3. 여러 가지 파일 포맷 다루기
1) CSV 파일
2) XML파일
3) JSON 파일
1-1) 인코딩과 디코딩
문자열 데이터를 변수에 저장하면 컴퓨터는 주기억장치 메모리 RAM에 저장한다.
RAM에 저장될 때 컴퓨터는 0과 1 즉, 이진 데이터로만 표현되기 때문에 이 데이터도 0과 1로 변환돼 저장된다.
어떻게 문자열을 이진수로 표현할까?
전 세계 문자를 모두 숫자로 표시할 수 있는 표준 코드인, 유니코드로 표현한다.
ord() : 해당 문자에 대응하는 유니코드 숫자 반환
chr() : 해당 유니코드 숫자에 대응하는 문자를 반환
1-2) 문자열 다루기
1) 이스케이프 문자
직접 입력할 수 없는 일부 문자를 문자열에 포함시킬 수 있는 특수 문자

2) startswith, endswith
처음 시작하는 문자, 끝나는 문자 찾는 용도
3) 공백 문자 처리 trimming
4) 대소문자 관련
- upper() : 모든 문자를 대문자로 변환합니다.
- lower() : 모든 문자를 소문자로 변환합니다.
- capitalize() : 첫 글자만 대문자로 변환합니다.
5) isX
- isupper() : 문자열이 모두 대문자로만 되어 있으면 True, 그렇지 않으면 False를 반환
- islower() : 문자열이 모두 소문자로만 되어 있으면 True, 그렇지 않으면 False를 반환
- istitle(): 문자열의 첫 글자만 대문자로 되어 있으면 True, 그렇지 않으면 False를 반환
- isalpha(): 문자열이 모두 알파벳 문자로만 되어 있으면 True, 그렇지 않으면 False를 반환
- isalnum(): 문자열이 모두 알파벳 문자와 숫자로만 되어 있으면 True, 그렇지 않으면 False를 반환
- isdecimal(): 문자열이 모두 숫자로만 되어 있으면 True, 그렇지 않으면 False를 반환
6) join()과 split()
#- join()
stages = ['apple', 'banana', 'cd']
",".join(stages)
'apple,banana,cd'
# split()
'apple,banana,cd'.split(',')
# ['apple', 'banana', 'cd']
7) replace()
replace(s1, s2) 형태로 문자열 내 문자열 s1을 s2로 바꿉니다.
1-3) 정규 표현식
import re
sent = 'I can do it!'
pattern = re.sub("I", "You", sent)
pattern
정규 표현식은 특정 규칙을 가진 문자열의 집합을 표현하는 형식 언어로, 찾고자 하는 문자열 패턴을 정의하고 기존 문자열과 일치하는지를 비교하여 문자열을 검색하거나 다른 문자열로 치환하는 데 사용
import re -> compile()
#1단계 : "the"라는 패턴을 컴파일한 후 패턴 객체를 리턴
pattern = re.compile("the")
# 2단계 : 컴파일된 패턴 객체를 활용하여 다른 텍스트에서 검색을 수행
pattern.findall('of the people, for the people, by the people')
# 1단계+2단계
re.findall('the', 'of the people, for the people, by the people')
메서드
- search() : 일치하는 패턴 찾기 (일치 패턴이 있으면 MatchObject를 반환합니다)
- match() : search()와 비슷하지만, 처음부터 패턴이 검색 대상과 일치해야 합니다.
- findall() : 일치하는 모든 패턴 찾기 (모든 일치 패턴을 리스트에 담아서 반환합니다)
- split() : 패턴으로 나누기
- sub() : 일치하는 패턴으로 대체하기
패턴 : 특수문자, 메타 문자
- [ ] : 문자
- - : 범위
- . : 하나의 문자
- ? : 0회 또는 1회 반복
- * : 0회 이상 반복
- + : 1회 이상 반복
- {m, n} : m ~ n
- \d : 숫자, [0-9]와 동일
- \D : 비 숫자, [^0-9]와 동일
- \w : 알파벳 문자 + 숫자 + _, [a-zA-Z0-9_]와 동일
- \W : 비 알파벳 문자 + 비숫자, [^a-zA-Z0-9_]와 동일
- \s : 공백 문자, [ \t\n\r\f\v]와 동일
- \S : 비 공백 문자, [^ \t\n\r\f\v]와 동일
- \b : 단어 경계
- \B : 비 단어 경계
- \t : 가로 탭(tab)
- \v : 세로 탭(vertical tab)
- \f : 폼 피드
- \n : 라인 피드(개행문자)
- \r : 캐리지 리턴(원시 문자열)
#- 전화번호(숫자, 기호)
phonenumber = re.compile(r'\d\d\d-\d\d\d\d-\d\d\d\d')
# phonenumber = re.compile(r'\d{3}-\d{3}-\d{4}') 같은 표현
# phonenumber = re.compile(r'(\d{3}-){2}\d{4}') 같은 표현
phone = phonenumber.search('This is my phone number 010-1111-1111')
if phone:
print(phone.group())
print('------')
phone = phonenumber.match ('This is my phone number 010-1111-1111')
if phone:
print(phone.group())
# 010-1111-1111
# ------
구현 순서
- import re를 통해 정규식 모듈을 임포트
- re.compile() 함수로 Regex 객체 생성
- 검색할 문자열을 Regex 객체의 search() , findall() 메소드로 전달

2-1) 파일
write
f = open("hello.txt","w")
# open(파일명, 파일모드)
# 파일을 열고 파일 객체를 반환
for i in range(10):
f.write("안녕")
# write() 메서드로 '안녕'을 10번 쓰기
f.close()
# 작업이 끝나면 close() 메서드로 닫기
print("완료!")
read
with open("hello.txt", "r") as f:
print(f.read())with구문을 사용하여 파일을 열었기 때문에 파일 객체를 f로 받아서 f.read()를 통해 내용을 읽었다.
f.close()를 명시적으로 호출하지 않았는데, 그 이유는
with를 통해 open 된 객체는 with문이 종료될 때 자동으로 close 되는 것이 보장되기 때문이다.
- f.read() : 파일을 읽는다.
- f.readline() : 파일을 한 줄씩 읽는다.
- f.readlines() : 파일 안의 모든 줄을 읽어 그 값을 리스트로 반환한다.
- f.write(str) : 파일에 쓴다. 문자열 타입을 인자로 받는다.
- f.writelines(str) : 파일에 인자를 한 줄씩 쓴다.
- f.close() : 파일을 닫는다.
- f.seek(offset) : 해당 파일의 위치(offset)를 찾아 파일의 커서를 옮긴다. 파일의 처음 위치는 0이다.
- f.tell(): 현재 커서의 위치를 반환한다.
2-2) 디렉터리
- Window 운영 체제 : C:\
- Linux 계열 운영 체제 : /
2-3) 모듈과 패키지
파이썬 파일은 어디에 저장될까?
- sys
- os
- glob
파이썬 프로그램의 실행 파일(python.exe)은 어디에 저장돼 있는지 확인
import sys
sys.executable
pip나 conda 명령어를 통해 설치한 라이브러리 관련 파일 위치 찾기
sys.path
pip 등을 통해 현재 실행 중인 파일에 명시적으로 라이브러리 설치 -> 내가 자주 쓰는 코드
import sys
!{sys.executable} -m pip install 패키지명
(커널과 pip 환경이 다를 때는 다음과 같이 커널 기준으로 명시적 설치해 주면 되는데,
주피터 노트북 환경에서 !pip install 패키지명으로 해도 pip list에 들어가 있지 않거나 설치가 되지 않은 경우에
위의 코드를 사용해 주면 웬만한 설치 문제는 다 해결된다.)
파이썬 모듈 및 패키지 개념 정리
- sys.path : 현재 폴더와 파이썬 모듈들이 저장되는 위치를 리스트 형태로 반환
- sys.path.append() : 자신이 만든 모듈의 경로를 append 함수를 이용해서 추가함. 그 후 추가한 디렉터리에 있는 파이썬 모듈을 불러와 사용할 수 있다.
- os.chdir() : 디렉터리 위치 변경
- os.getcwd() : 현재 자신의 디렉터리 위치를 반환
- os.mkdir() : 디렉터리 생성
- os.rmdir() : 디렉터리 삭제 (단, 디렉터리가 비어 있을 경우)
- glob.glob() : 해당 경로 안의 디렉터리나 파일들을 리스트 형태로 반환
- os.path.join() : 경로(path)를 병합하여 새 경로 생성
- os.listdir() : 디렉터리 안의 파일 및 서브 디렉터리를 리스트 형태로 반환
- os.path.exists() : 파일 혹은 디렉터리의 경로 존재 여부 확인
- os.path.isfile() : 파일 경로의 존재 여부 확인
- os.path.isdir() : 디렉터리 경로의 존재 여부 확인
- os.path.getsize() : 파일의 크기 확인
3-1) CSV 파일
billboardchart = {
1 : ["Tho Box","Roddy Ricch","2019-12-19"],
2 : ["Don't Start Now", "Dua Lipa", "2019-11-01"],
3 : ["Life Is Good", "Future Featuring Drake", "2020-02-10"],
4 : ["Blinding", "The Weeknd", "2019-11-29"],
5 : ["Circles", "Post Malone","2019-08-30"]}
with open("billboardchart.csv","w") as f:
for i in billboardchart.values():
data = ",".join(i)
f.write(data+"\n")
print("csv 파일 생성 완료")
import csv
header = ["title", "singer", "released date"] # 각 컬럼이 어떤 의미인지 추가
with open("billboardchart.csv","r") as inputfile:
with open("billboardchart_out.csv","w", newline='\n') as outputfile:
fi = csv.reader(inputfile, delimiter=',')
fo = csv.writer(outputfile, delimiter=',')
fo.writerow(header)
for row in fi:
fo.writerow(row)
print("칼럼 의미 추가")
import pandas as pd
import csv
fields = ["title", "singer", "released date"]
rows = [ ["Tho Box","Roddy Ricch","2019-12-19"],
["Don't Start Now", "Dua Lipa", "2019-11-01"],
["Life Is Good", "Future Featuring Drake", "2020-02-10"],
["Blinding", "The Weeknd", "2019-11-29"],
["Circles", "Post Malone","2019-08-30"]]
df=pd.DataFrame(rows, columns=fields)
df.to_csv('data.csv',index=False) # csv 파일로 저장
동일한 내용을 csv.writer 이용하여 코드 구현
filename = "data2.csv"
with open(filename, 'w+', newline='\n') as csv_file:
csv_writer = csv.writer(csv_file)
csv_writer.writerow(fields)
csv_writer.writerows(rows)
print("done")

csv -> dataframe으로 변환하여 데이터 분석 등 사용자가 편집하기 용이한 형태로 변환한다.
df = pd.read_csv('data3.csv')
df.head()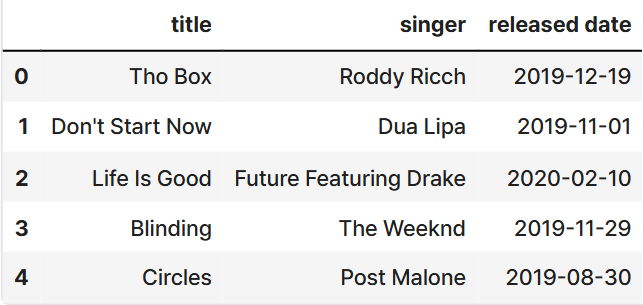
3-2) XML 파일
API에서 데이터를 요청하고 저장할 때 XML이나 JSON 형식을 이용해 데이터를 교환한다.
- Element() : 태그 생성
- SubElement() : 자식 태그 생성
- tag : 태그 이름
- text : 텍스트 내용 생성
- attrib : 속성 생성
- write() : XML 파일로 저장
import xml.etree.ElementTree as ET
person = ET.Element("Person")
name = ET.Element("name")
name.text = "홍길동"
person.append(name)
age = ET.Element("age")
age.text = "24"
person.append(age)
ET.SubElement(person, 'place').text = '송파'
ET.dump(person)
<Person>
<name>이펠</name>
<age>28</age>
<place>강남</place>
</Person>
XML 파일로 저장하기
ET.ElementTree(person).write('person.xml') # XML 파일로 저장
XML 파싱 하기
어떤 문자열을 의미 있는 토큰(token)으로 분해해, 문법적 의미와 구조를 반영한 파스 트리(parse tree)를 만드는 과정이다.
XML 문서를 파싱 하게 되면 특정 태그명이나 속성값 등을 불러올 수 있다.
3-3) JSON 파일
웹 브라우저와 다른 애플리케이션 사이에서 HTTP 요청으로 데이터를 보낼 때 널리 사용하는 표준 파일 포맷 중 하나
XML과 더불어 웹 API나 config 데이터를 전송할 때 많이 쓰인다.
person = {
"first name" : "Gildong",
"last name" : "Hong",
"age" : 24,
"nationality" : "South Korea",
"education" : [{"degree":"B.S degree", "university":"Seoul university", "major": "computer engineering", "graduated year":2025}]
}
JSON 파싱
1. json 파일 저장
import json
person = {
"first name" : "Yuna",
"last name" : "Jung",
"age" : 33,
"nationality" : "South Korea",
"education" : [{"degree":"B.S degree", "university":"Daehan university", "major": "mechanical engineering", "graduated year":2010}]
}
with open("person.json", "w") as f:
json.dump(person , f)
2. json 파일 읽기
import json
with open("person.json", "r", encoding="utf-8") as f:
contents = json.load(f)
print(contents["first name"])
print(contents["education"])'Deep Learning' 카테고리의 다른 글
| [딥러닝] 텍스트의 분포로 벡터화 하기(BoW, DTM&코사인 유사도, TF-IDF, LSA&LDA, soynlp) (0) | 2025.06.16 |
|---|---|
| [딥러닝] 딥러닝 알아보기2 - 텐서 생성, 텐서 타입, 텐서 타입 변환, 텐서 연산, 다양한 함수 정리 (1) | 2025.06.13 |
| [딥러닝] 딥러닝 알아보기1 - 인공 신경망, 퍼셉트론, 은닉층, 딥러닝 문제점 및 해결 방법 (1) | 2025.06.12 |

